
MotherDuck社の公式ブログのチュートリアル「DuckDB Tutorial For Beginners」をやってみた

さがらです。
MotherDuck社の公式ブログのチュートリアル「DuckDB Tutorial For Beginners」をやってみたので、本記事でその内容をまとめてみます。
検証環境
- OS:Ubuntu 24.04 LTS(WSL2)
事前準備
下記のリポジトリのフォルダからサンプルデータのファイルをダウンロードしておきます。(今回は作業ディレクトリの中にdataフォルダを作り、その中に格納します。)
インストール
以下のコマンドを実行して、インストールします。(最新のインストール用のコマンドはこちらのドキュメントも併せてご覧ください。)
# 最新バージョンをダウンロード
wget https://github.com/duckdb/duckdb/releases/download/v1.1.0/duckdb_cli-linux-amd64.zip
# 解凍
unzip duckdb_cli-linux-amd64.zip
# 実行権限を付与
chmod +x duckdb
# オプション:システム全体で使用できるようにする
sudo mv duckdb /usr/local/bin/
この後、duckdbとコマンドを実行し、下記のように表示されればOKです。
$ duckdb
v1.1.0 fa5c2fe15f
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
D
DuckDBでファイルにクエリする
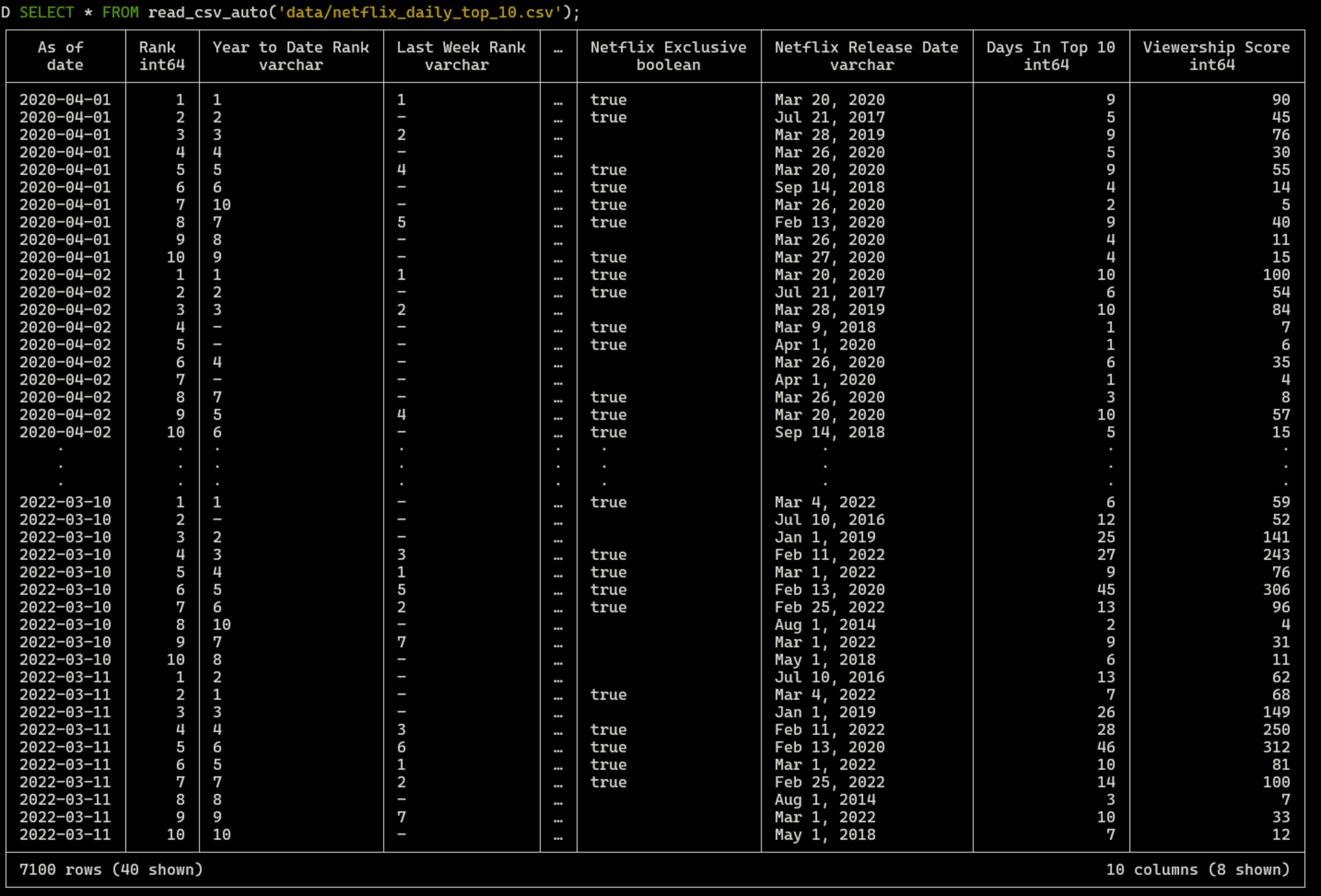
DuckDB起動後、下記のようにread_csv_auto関数を用いると、CSVファイルに対してクエリを実行する事ができます。
SELECT * FROM read_csv_auto('data/netflix_daily_top_10.csv');
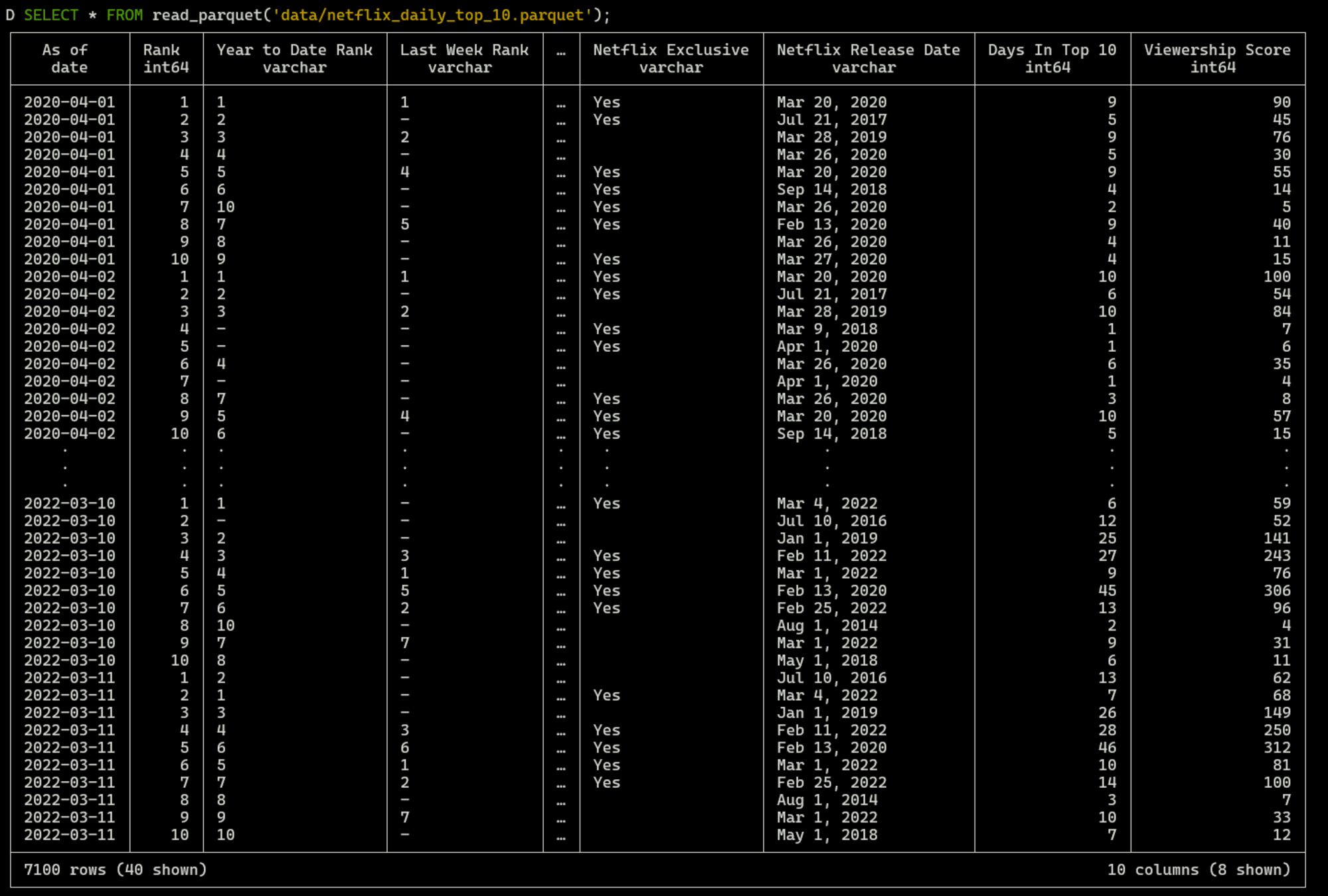
read_parquet関数を用いることで、parquetファイルに対してクエリを実行することができます。
SELECT * FROM read_parquet('data/netflix_daily_top_10.parquet');
DuckDBでのテーブルの永続化
duckdbコマンドを実行する際に任意のデータベースファイルへのパスを指定した上でDuckDBを起動してテーブルを作成すると、後続のDDL文でテーブルを永続化することができます。
mkdir database
duckdb database/myawesomedb.db
DuckDB起動後、ダウンロードしたCSVファイルを元にCTASのクエリを実行します。
CREATE TABLE netflix_top10 AS SELECT * FROM read_csv_auto('data/netflix_daily_top_10.csv');
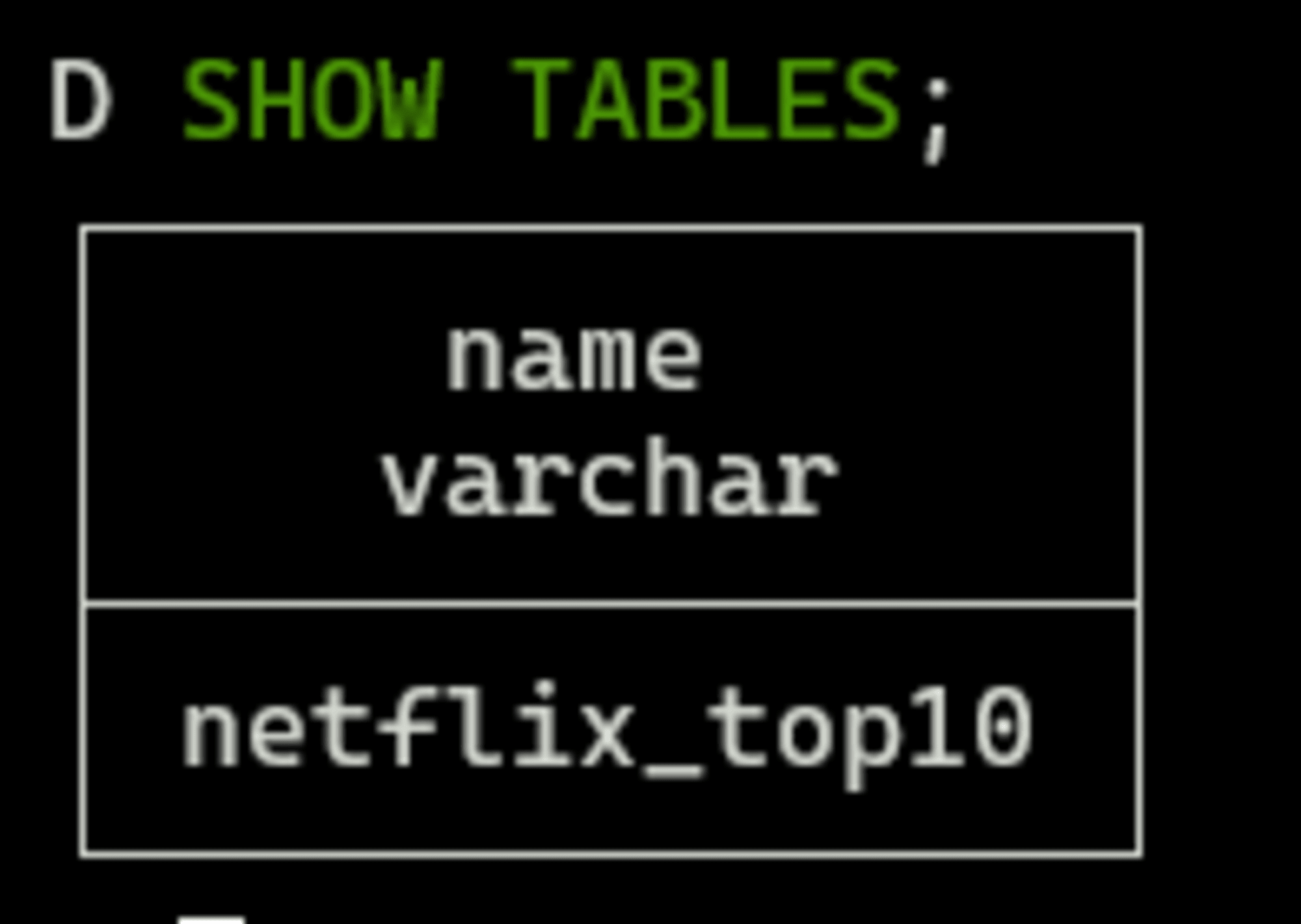
このあと、SHOW TABLESを実行すると、下記のように表示され、無事にテーブルが作られたことがわかります。
SHOW TABLES;
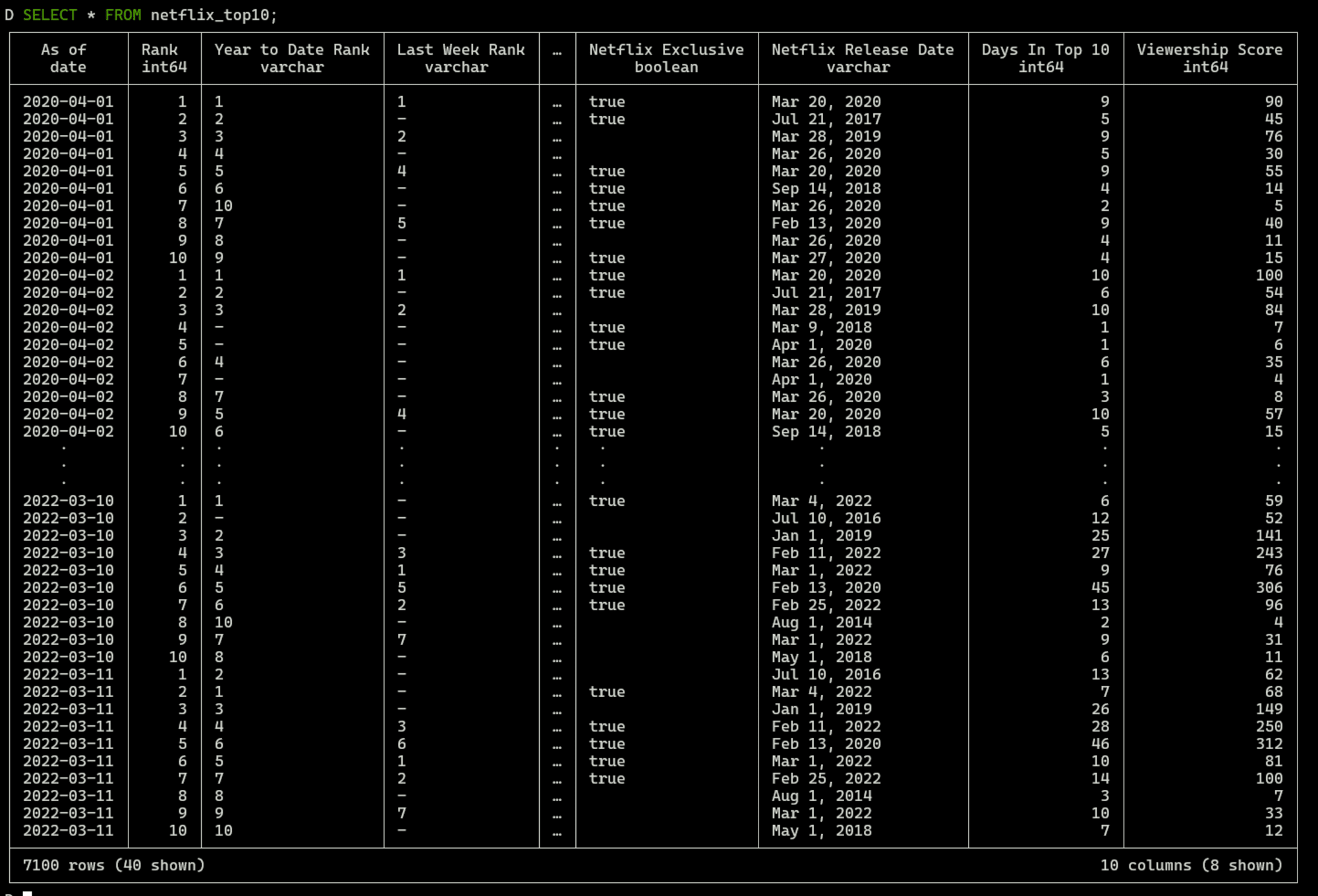
もちろん作成されたテーブルに対してSELECT *のクエリを実行することも出来ます。
SELECT * FROM netflix_top10;
modeの変更
DuckDBではmodeを変更することで、出力されるデータの形式を変更することが出来ます。
mode lineについて
- Before(通常モード)

- After

mode markdownについて
- Before(通常モード)
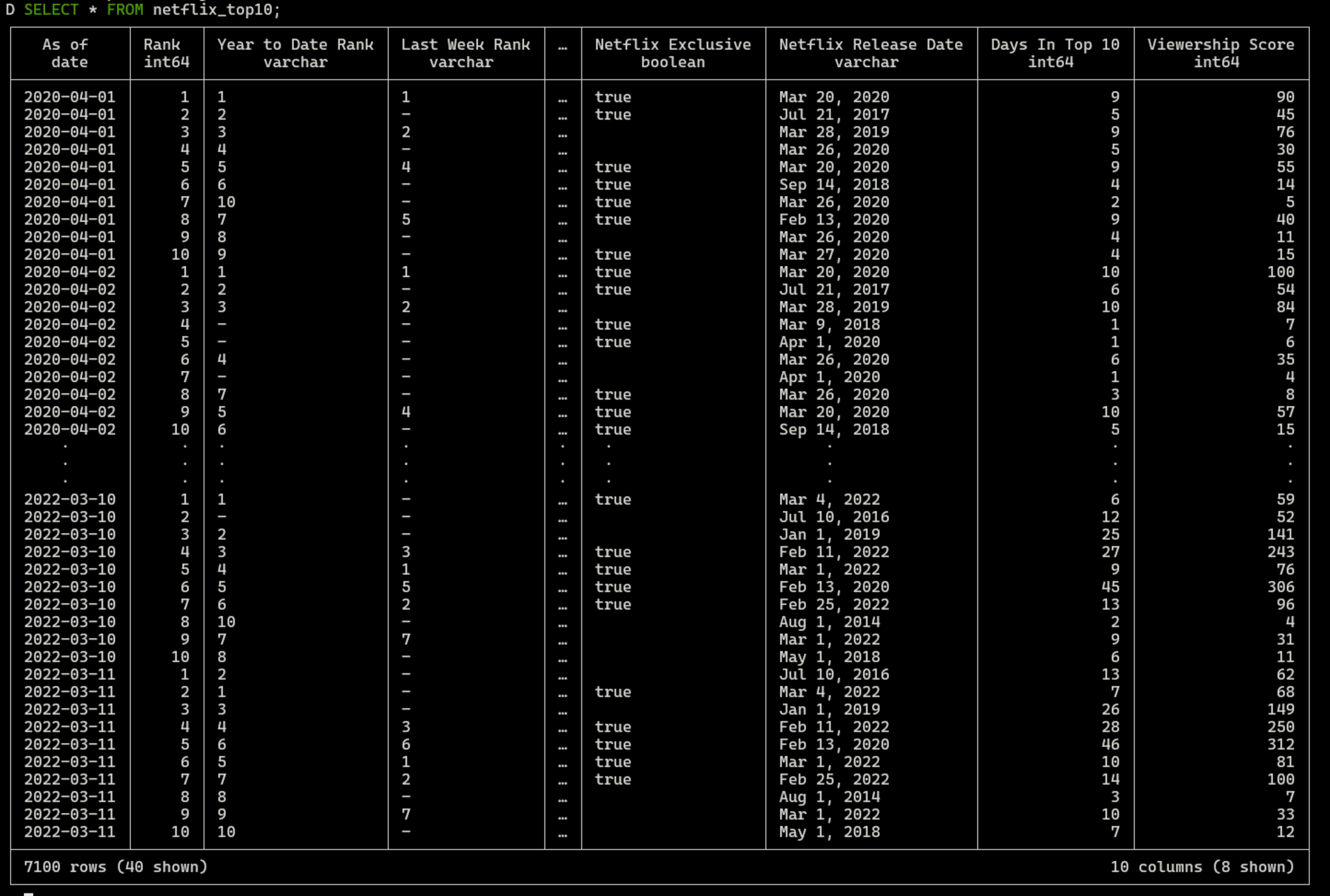
- After
※7000行のテーブルだと全レコード下図のように出力されるため注意しましょう…
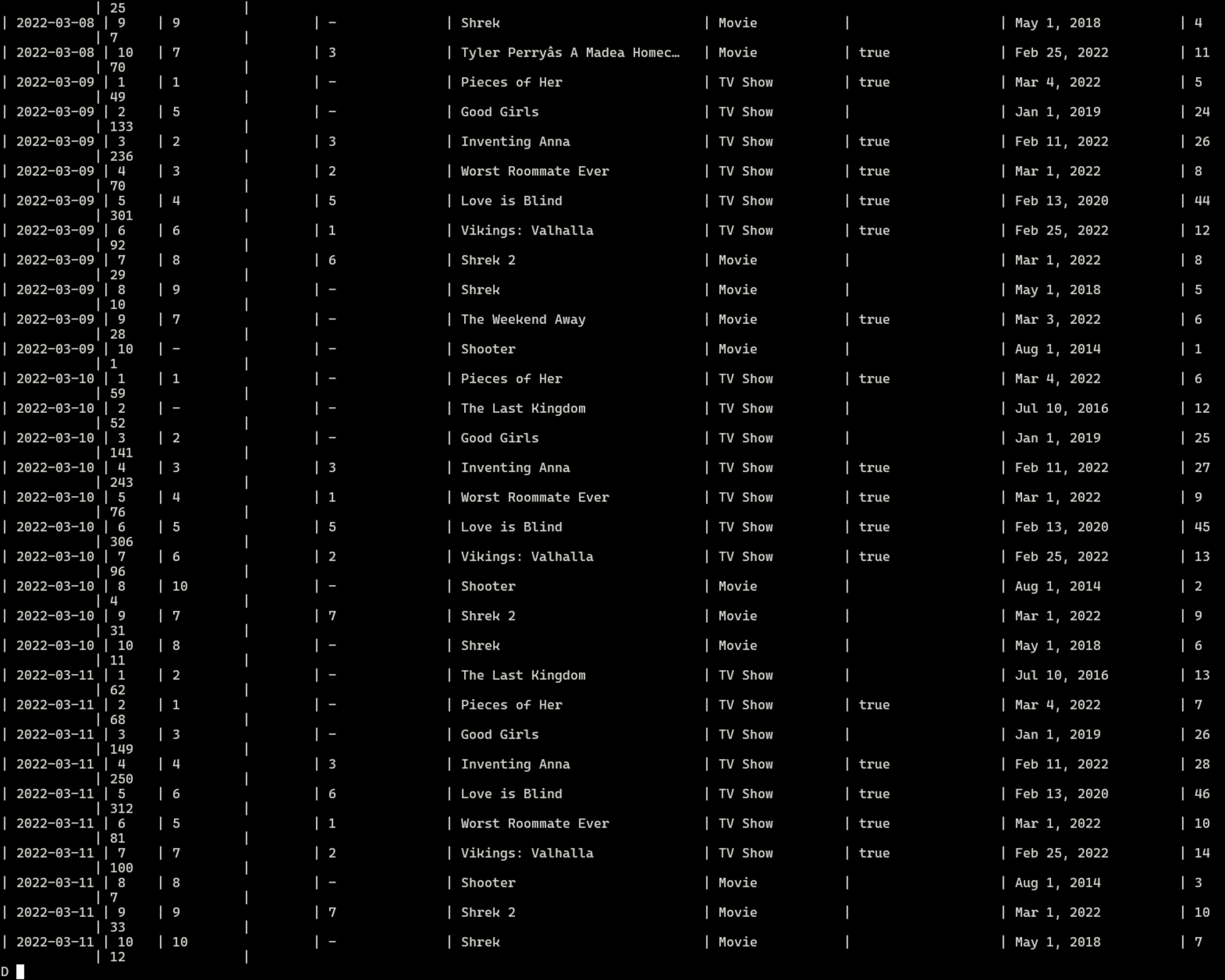
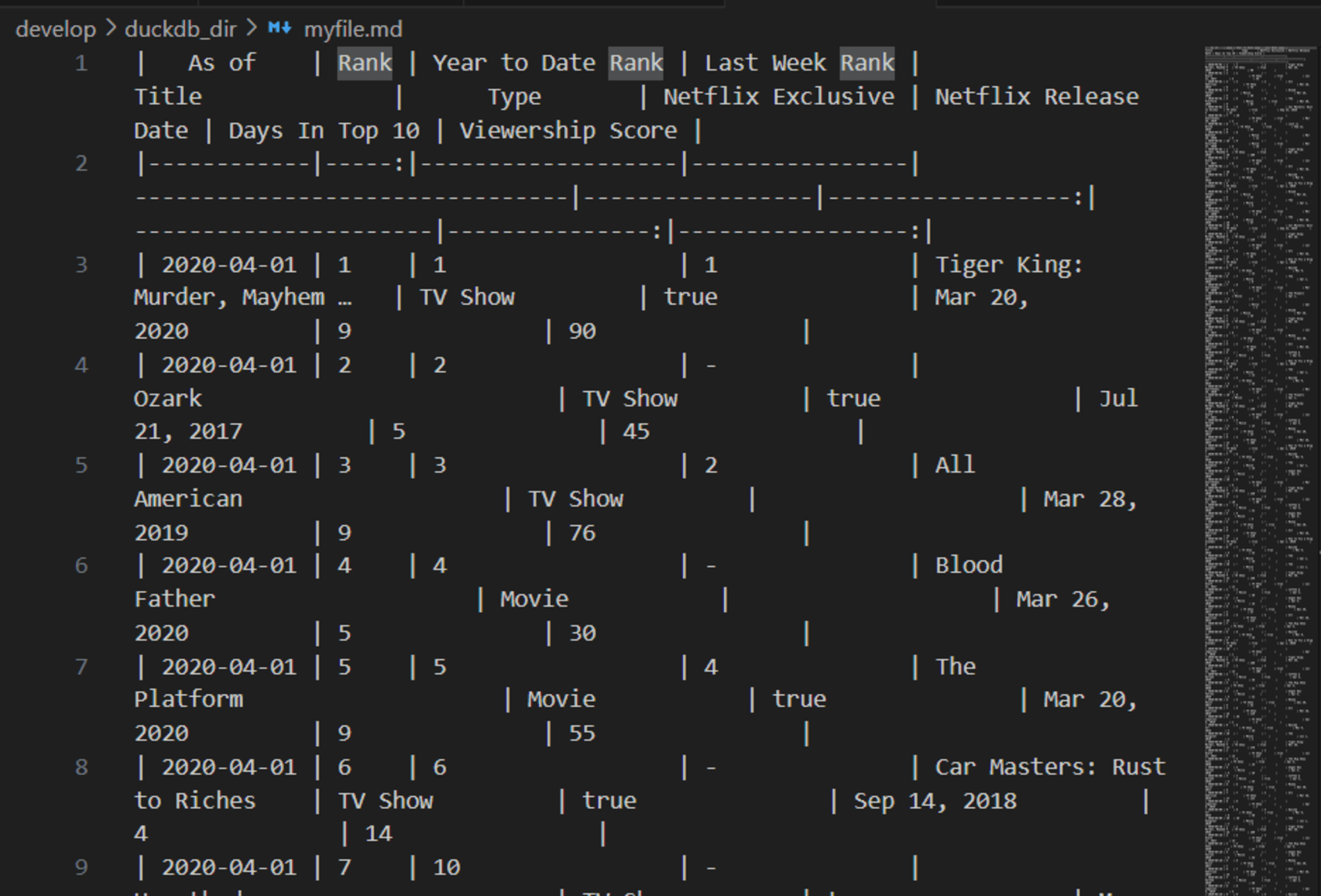
また、.output myfile.mdのように実行すると、その後に実行されたクエリの内容を指定したファイルにMarkdown形式で出力してくれます。
.mode markdown
.output myfile.md
SELECT * FROM netflix_top10;
CLIからDuckDBを実行
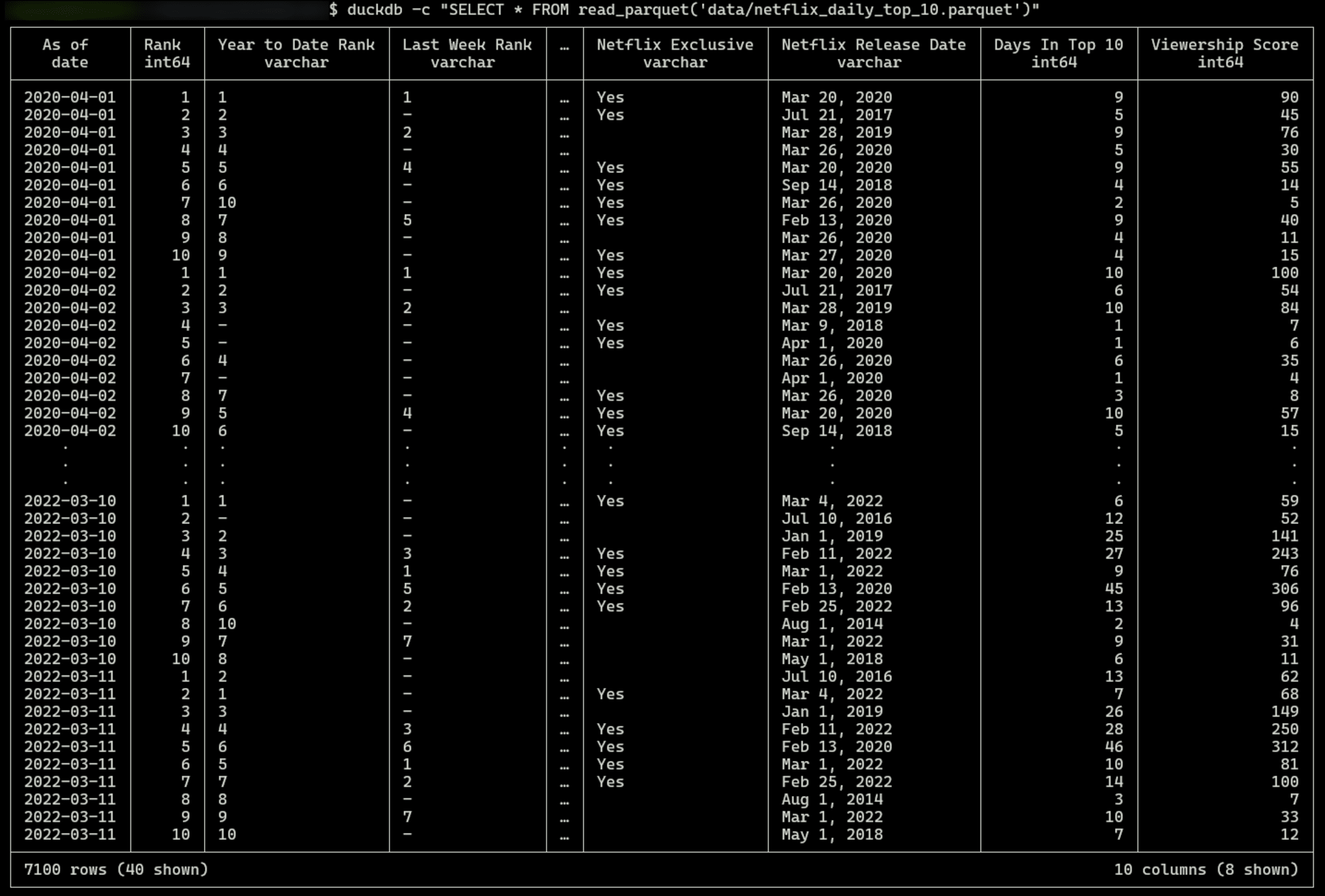
下記のようにコマンドラインからオプションを付けて実行すると、直接DuckDBのコマンドを実行できます。
duckdb -c "SELECT * FROM read_parquet('data/netflix_daily_top_10.parquet')"
一つ例としては、CSVをparquetに変換ということも可能です。
duckdb -c "COPY 'data/netflix_daily_top_10.csv' TO 'output_netflix_daily_top_10.parquet' WITH (FORMAT 'PARQUET');"

Extensionの操作
DuckDBには「Extension」というDuckDBにインストールできるパッケージのような機能が備わっています。
下記のクエリを実行すると、利用できる拡張機能の一覧が確認できます。
SELECT * FROM duckdb_extensions();
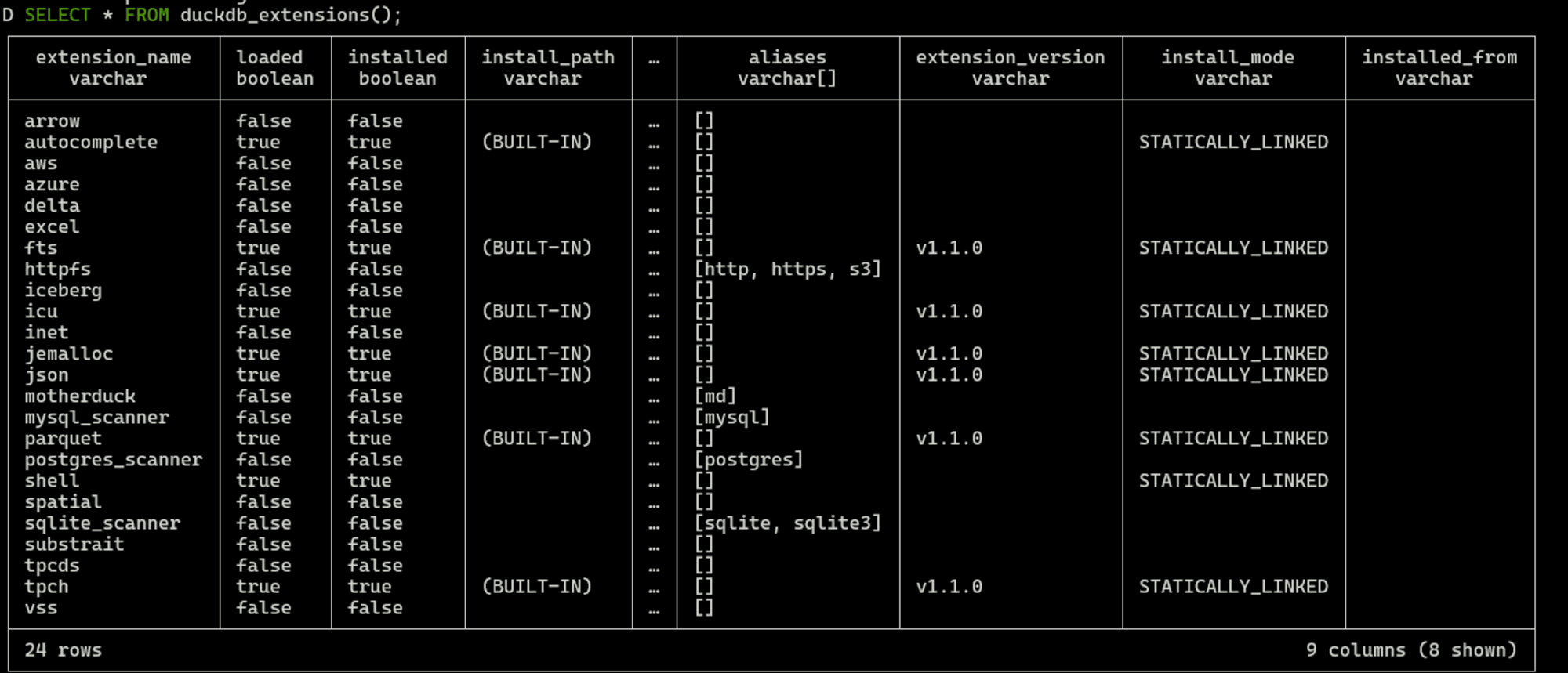
今回は、HTTPSおよびS3経由でリモートファイルの読み取り/書き込みを可能にする拡張機能のhttpfsをインストールしてみます。下記のコマンドをDuckDB上で実行すればOKです。
INSTALL httpfs;
LOAD httpfs;
S3に対してDuckDBからクエリを実行
最後に、DuckDBが管理しているパブリックのS3に対してDuckDBからクエリを実行してみます。
まず、下記のクエリを実行します。
-- Install extensions
INSTALL httpfs;
LOAD httpfs;
-- Minimum configuration for loading S3 dataset if the bucket is public
SET s3_region='us-east-1';
次に以下のクエリを実行してS3に保存されているparquetファイルからテーブルを作成します。
CREATE TABLE netflix AS SELECT * FROM read_parquet('s3://duckdb-md-dataset-121/netflix_daily_top_10.parquet');
SHOW TABLES;

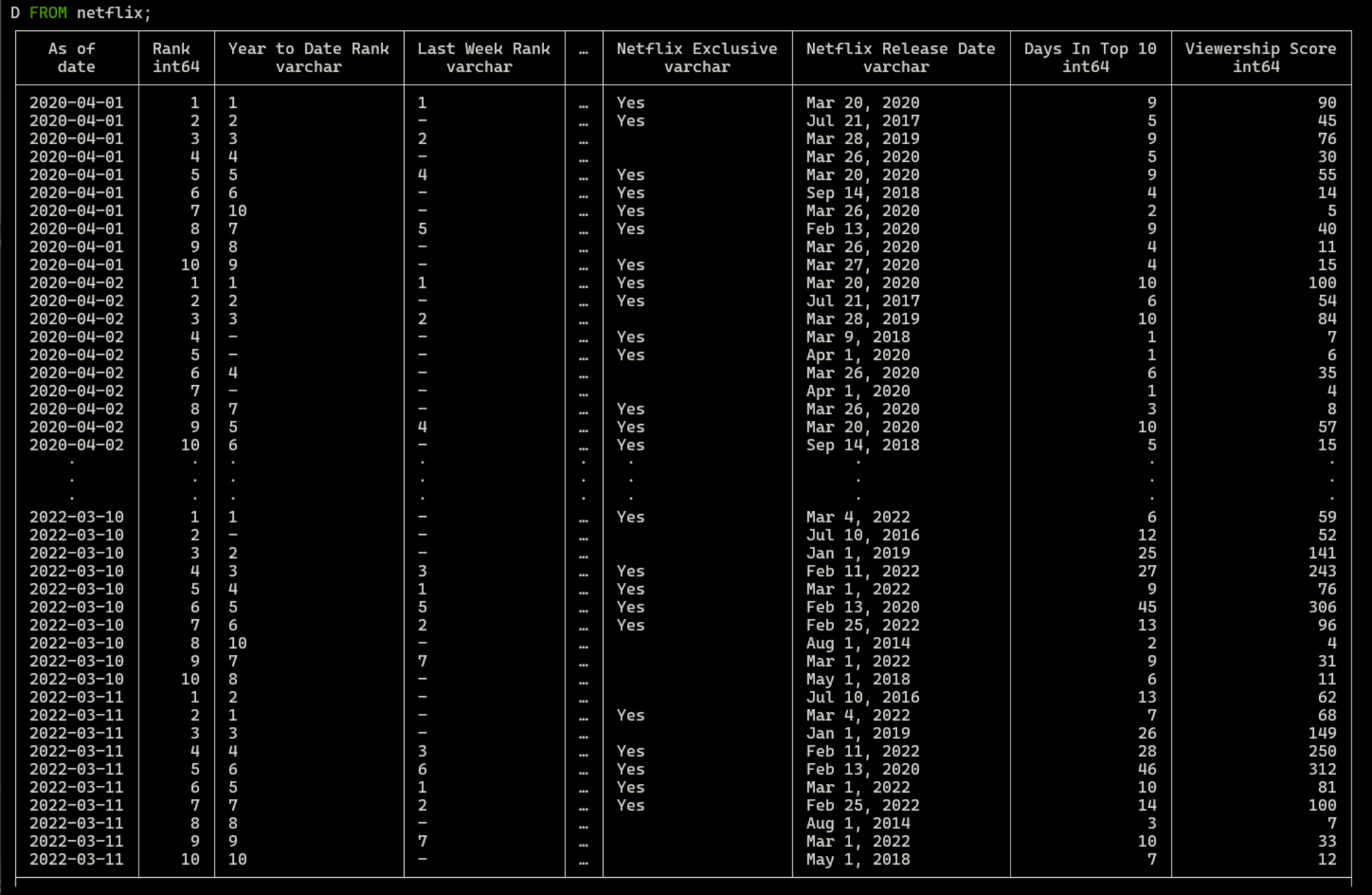
参考までに、FROM netflixというコマンドだけ実行しても、SELECT *と同等の結果を得ることが出来ます。
FROM netflix;
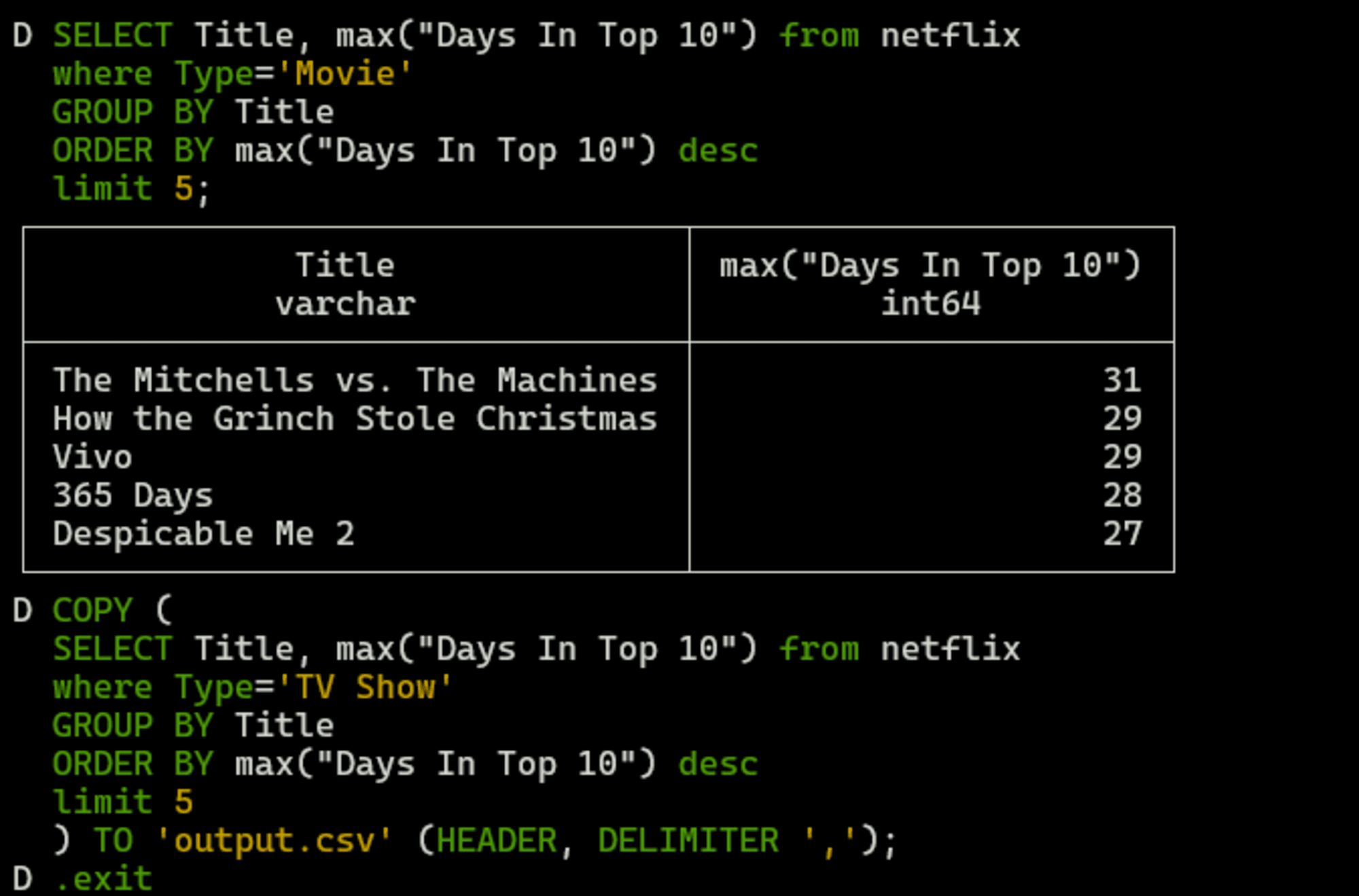
最も視聴された映画を分析するためのクエリを記述し、その実行結果をCSVとしてアウトプットしてみます。
SELECT Title, max("Days In Top 10") from netflix
where Type='Movie'
GROUP BY Title
ORDER BY max("Days In Top 10") desc
limit 5;
COPY (
SELECT Title, max("Days In Top 10") from netflix
where Type='TV Show'
GROUP BY Title
ORDER BY max("Days In Top 10") desc
limit 5
) TO 'output.csv' (HEADER, DELIMITER ',');
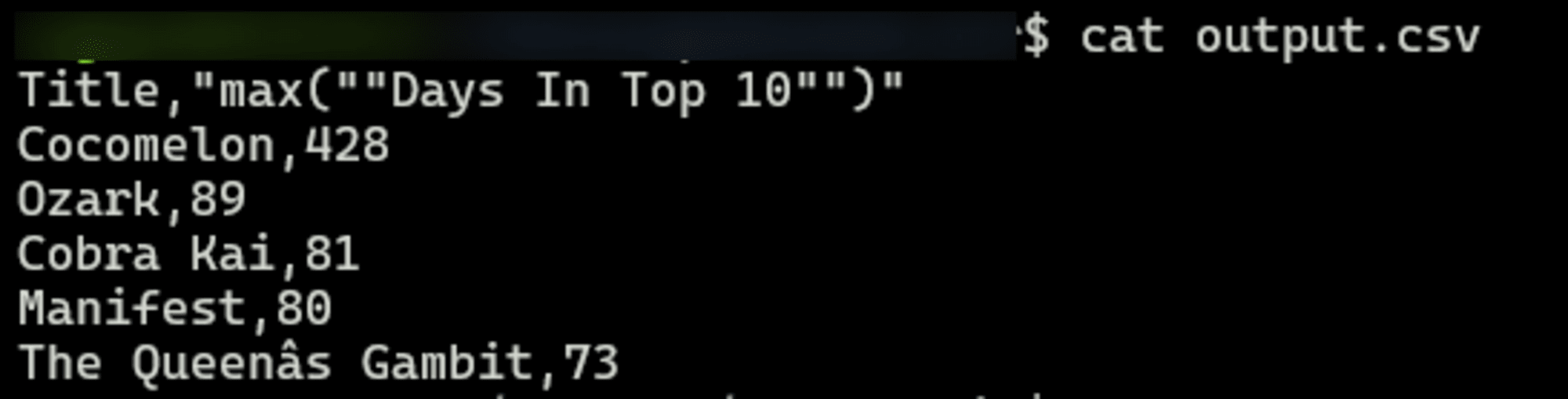
最後に
MotherDuck社の公式ブログのチュートリアル「DuckDB Tutorial For Beginners」をやってみました。
DuckDBの記事などはよく読んでいたのですが、改めて自分で触ってみて、とても簡単にcsvやparquetに対してクエリできるのが素晴らしいなと感じました!